Advanced example
Disaster Recovery
Multi-provider NodePool, automatic failover, and node-loss handling.
./hack/simulate-disaster-recovery.sh --with-api-mock.
When your primary cloud has an outage, Cloudburst bursts to nodes on alternative providers. Two mechanisms work together:
- Automatic node-loss reconciliation: When a node leaves the cluster (VM terminated, provider failure), the controller detects it, transitions the NodeClaim to Deleting, cleans up, and frees capacity so the NodePool can create a replacement. No manual NodeClaim deletion.
- Policy-based failover: Update NodePool
allowedProvidersto steer new capacity away from the failed provider. Exclude the primary, allow fallbacks—new pending pods trigger provisioning on the fallback cloud.
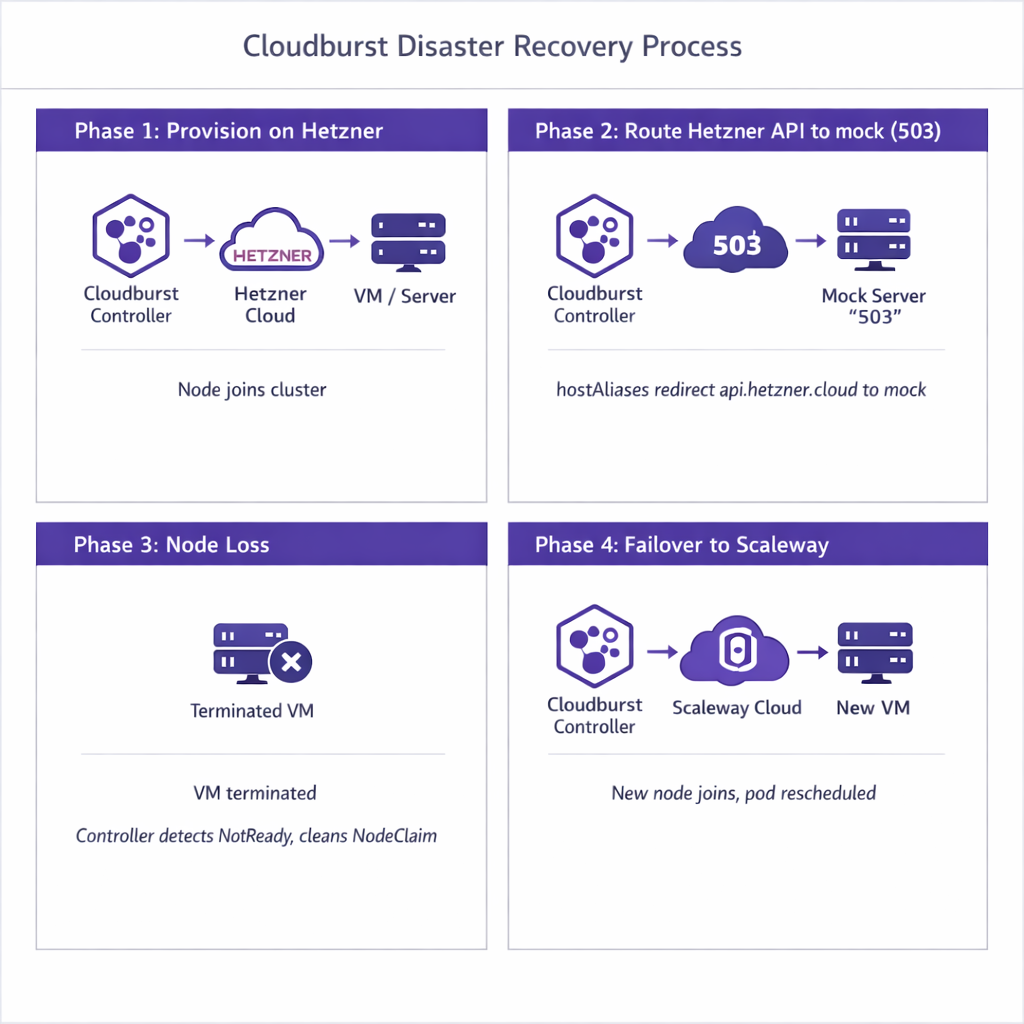
Simulation flow (4 phases)
Each phase below describes exactly what the script does and what happens in the cluster.
Phase 1: Initial provision on Hetzner
The script creates the NodePool with allowedProviders=[hetzner, scaleway] and the Deployment (1 replica). CloudBroker is seeded so Hetzner ranks first (cheapest). The Deployment pod is Pending because no node matches cloudburst.io/nodepool=dr-nodepool. The NodePool controller sees the unschedulable pod, asks CloudBroker for a recommendation, and receives Hetzner. The controller provisions a VM on Hetzner via the real API (the mock is not yet in the path), bootstraps it (Tailscale, kubelet, kubeadm join), and the node joins the cluster. Once the node is Ready, the scheduler places the pod on it. At this point the workload runs on a Hetzner burst node.
Phase 2: Route Hetzner API to mock
The script patches the Cloudburst controller Deployment with hostAliases: api.hetzner.cloud resolves to the in-cluster mock service IP. It also sets HETZNER_INSECURE_SKIP_VERIFY=true so the controller accepts the mock's self-signed TLS. After the controller rollout completes, any call the controller makes to api.hetzner.cloud goes to the mock instead of the real Hetzner API. The mock returns 503 Service Unavailable on POST /v1/servers (create instance), simulating a Hetzner outage. Other Hetzner endpoints are proxied to the real API.
Phase 3: Simulate node loss
The script reads the instanceID from the NodeClaim status (e.g. hetzner/fsn1/12345) and deletes the cloud instance directly via the Hetzner API—outside the controller, as if the provider had terminated the VM or a human had deleted it. The Kubernetes node object remains, but the node goes NotReady because the VM is gone. The controller's node-loss reconciliation detects the unreachable node after NodeUnreachableGracePeriod (90 seconds in the DR test). It transitions the NodeClaim to Deleting, cleans up the NodeClaim, and removes the node object. The Deployment's pod was on that node; it is evicted. The Deployment controller recreates the pod, which becomes Pending again.
Phase 4: Failover to Scaleway
The NodePool controller sees the new pending pod and creates a NodeClaim. It asks CloudBroker for a recommendation; CloudBroker returns Hetzner first (still cheapest). The controller tries to create a VM on Hetzner—but the request goes to the mock (from Phase 2), which returns 503. The controller automatically falls back to the next recommendation (Scaleway), provisions a VM on Scaleway via the real API, bootstraps it, and the node joins. The scheduler places the pod on the Scaleway node. The workload has failed over from Hetzner to Scaleway without any manual NodePool or NodeClaim changes. Disaster recovery demonstrated.
1. Create secrets
# Tailscale auth key (required by NodeClass)
kubectl create secret generic tailscale-auth --from-literal=authkey="<YOUR_TAILSCALE_AUTHKEY>" -n default
# Hetzner API token
kubectl create secret generic hetzner-api-token --from-literal=HETZNER_API_TOKEN="<YOUR_HETZNER_API_TOKEN>" -n default
# Scaleway credentials
kubectl create secret generic scaleway-api-keys --from-literal=SCW_SECRET_KEY="<YOUR_SCW_SECRET_KEY>" -n default2. NodePool
# Both providers allowed; CloudBroker ranks them; controller tries in order
apiVersion: cloudburst.io/v1alpha1
kind: NodePool
metadata:
name: dr-nodepool
namespace: default
spec:
requirements:
regionConstraint: "ANY"
arch: ["x86_64"]
maxPriceEurPerHour: 0.50
allowedProviders: ["hetzner", "scaleway"]
limits:
maxNodes: 2
minNodes: 0
template:
labels:
cloudburst.io/nodepool: "dr-nodepool"
disruption:
ttlSecondsAfterEmpty: 60
ttlSecondsUntilExpired: 3600
weight: 13. NodeClass
# Config for both Hetzner and Scaleway
apiVersion: cloudburst.io/v1alpha1
kind: NodeClass
metadata:
name: dr-nodeclass
namespace: default
spec:
hetzner:
location: "fsn1"
apiTokenSecretRef:
name: hetzner-api-token
key: HETZNER_API_TOKEN
scaleway:
zone: "fr-par-1"
projectID: "your-scaleway-project-id"
image: "ubuntu_jammy"
apiKeySecretRef:
name: scaleway-api-keys
key: SCW_SECRET_KEY
join:
hostApiServer: "https://<HOST_TAILSCALE_IP>:6443"
kindClusterName: "cloudburst"
tokenTtlMinutes: 60
tailscale:
authKeySecretRef:
name: tailscale-auth
key: authkey
bootstrap:
kubernetesVersion: "1.34.3"4. Deployment (triggers burst; targets DR nodepool)
# Controller provisions for pending pods; recreates after node loss
apiVersion: apps/v1
kind: Deployment
metadata:
name: dr-workload
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: dr-workload
template:
metadata:
labels:
app: dr-workload
spec:
nodeSelector:
cloudburst.io/nodepool: "dr-nodepool"
containers:
- name: workload
image: busybox:1.36
command: ["sleep", "infinity"]
resources:
requests:
cpu: "1500m"
memory: "2Gi"5. Apply and verify
# Save the manifests above to dr-example.yaml, then:
kubectl apply -f dr-example.yaml
# Watch NodeClaim creation and phase
kubectl get nodeclaims -w
# Once node is Ready, verify pod and node
kubectl get pods -o wide
kubectl get nodes -l cloudburst.io/nodepool=dr-nodepoolExpected output (Phase 1 — Hetzner provisioned):
NAME NODEPOOL PROVIDER REGION INSTANCE PHASE AGE
dr-nodepool-xxxxx dr-nodepool hetzner fsn1 cx31 Ready 3m6. Run the simulation script
# Requires --with-api-mock (deploys mock that returns 503 on Hetzner create)
./hack/simulate-disaster-recovery.sh --with-api-mock
# With existing cluster (Kind + CloudBroker already running)
./hack/simulate-disaster-recovery.sh --use-existing-cluster --with-api-mockProduction tips
- Automatic node-loss handling: When a VM is terminated (or node goes NotReady), the controller detects it after
NodeUnreachableGracePeriodand transitions the NodeClaim to Deleting. No manual node or NodeClaim deletion. - Provider failover: If CreateInstance fails (outage, quota, 503), the controller tries the next CloudBroker recommendation automatically. No NodePool patch required.
- Steering via allowedProviders: To exclude a known-bad provider proactively, patch
allowedProviders. Use monitoring or automation.