Advanced example
Multiple Unscheduled Pods
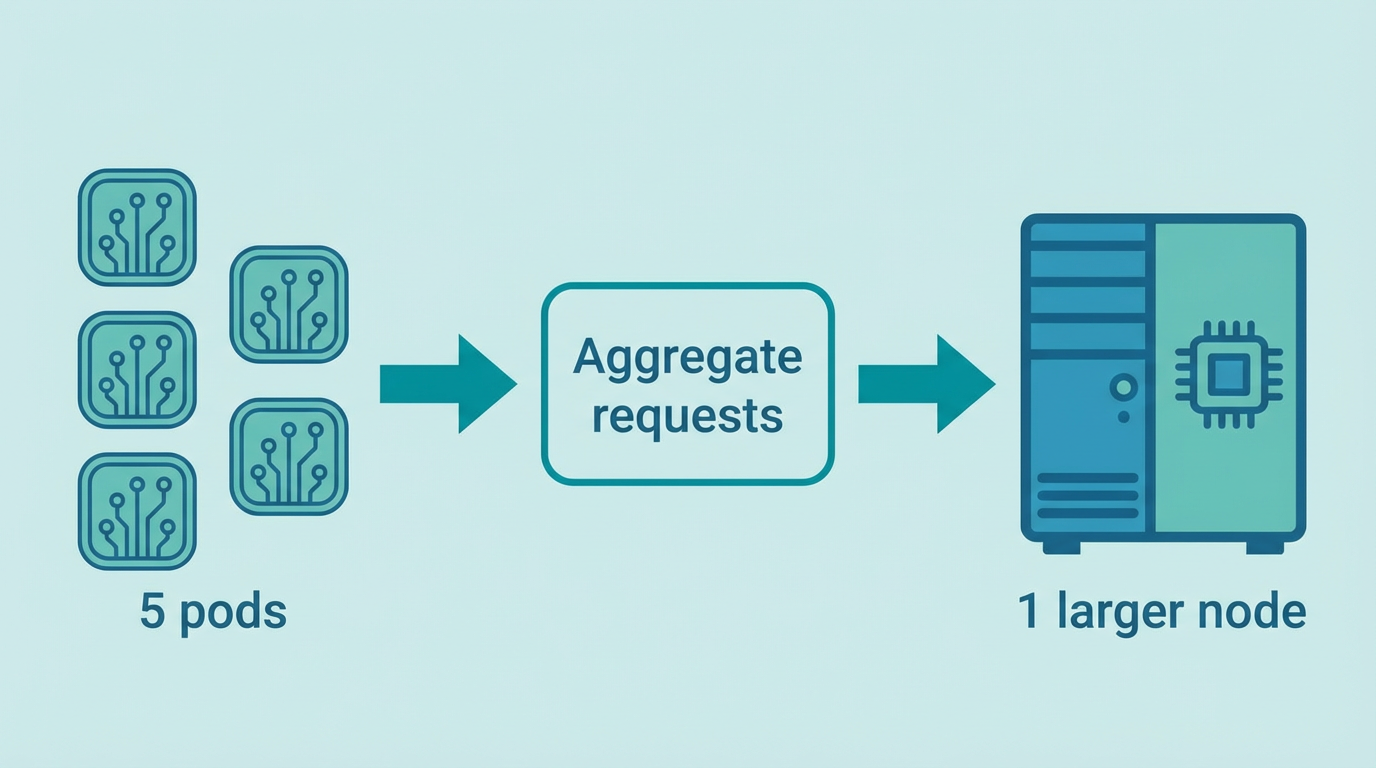
Demand aggregation: several pods trigger one larger node, not one node per pod.
When several pods are unschedulable at once, the NodePool controller handles them in one reconcile:
- Demand aggregation — CPU and memory requests are summed across all eligible unscheduled pods (Pending,
PodScheduled=False, reasonUnschedulable). Architecture is taken from the first pod that has one. - One node per reconcile — The controller creates at most one NodeClaim per reconcile. That node is sized to fit the combined demand via CloudBroker (min vCPU and RAM from the aggregate).
- Sequential scale-up — After creating a NodeClaim, it requeues in ~15 seconds. Another node is only created once the previous one is no longer active (e.g. Ready and drained, or Deleted).
Result: 5 pods that each need 2 CPU and 4Gi trigger one larger node sized for all of them. CloudBroker gets a request for a node with ≥10 vCPU and ≥20Gi RAM.
NodePool + NodeClass (Scaleway example)
Use any provider; Scaleway is shown for brevity. Ensure secrets exist.
apiVersion: cloudburst.io/v1alpha1
kind: NodePool
metadata:
name: multi-pod-nodepool
namespace: default
spec:
requirements:
regionConstraint: "EU"
arch: ["x86_64"]
maxPriceEurPerHour: 0.50
allowedProviders: ["scaleway"]
limits:
maxNodes: 3
minNodes: 0
template:
labels:
cloudburst.io/nodepool: "multi-pod-nodepool"
cloudburst.io/provider: "scaleway"
disruption:
ttlSecondsAfterEmpty: 60
ttlSecondsUntilExpired: 3600
weight: 1
---
apiVersion: cloudburst.io/v1alpha1
kind: NodeClass
metadata:
name: multi-pod-nodeclass
namespace: default
spec:
scaleway:
zone: "fr-par-1"
projectID: "your-scaleway-project-id"
image: "ubuntu_jammy"
apiKeySecretRef:
name: scaleway-credentials
key: SCW_SECRET_KEY
join:
hostApiServer: "https://<HOST_TAILSCALE_IP>:6443"
kindClusterName: "cloudburst"
tokenTtlMinutes: 60
tailscale:
authKeySecretRef:
name: tailscale-auth
key: authkey
bootstrap:
kubernetesVersion: "1.34.3"Deployment (5 replicas × 2 CPU, 4Gi each)
# 5 pods × 2 CPU + 4Gi = aggregate 10 vCPU, 20Gi → one larger node
apiVersion: apps/v1
kind: Deployment
metadata:
name: multi-pod-workload
namespace: default
spec:
replicas: 5
selector:
matchLabels:
app: multi-pod-workload
template:
metadata:
labels:
app: multi-pod-workload
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloudburst.io/provider
operator: In
values: ["scaleway"]
containers:
- name: workload
image: busybox:1.36
command: ["sleep", "infinity"]
resources:
requests:
cpu: "2000m"
memory: "4Gi"Apply and verify
# 1. Apply NodePool + NodeClass first
kubectl apply -f multi-pod-nodepool.yaml
kubectl apply -f multi-pod-nodeclass.yaml
# 2. Apply Deployment (5 pods will be Pending)
kubectl apply -f multi-pod-deployment.yaml
# 3. Watch: controller creates ONE NodeClaim for aggregate demand
kubectl get nodeclaims -w
# 4. Once node is Ready, all 5 pods schedule onto it
kubectl get pods -o wide
kubectl get nodes -l cloudburst.io/provider=scaleway
# 5. Verify node size (CloudBroker recommended ≥10 vCPU, ≥20Gi)
kubectl describe node -l cloudburst.io/provider=scaleway | grep -A5 "Allocated resources"